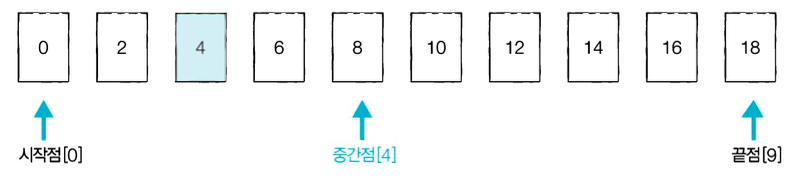
순차 탐색 리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 차례대로 확인하는 방법 보통 정렬되어있지 않은 리스트에서 데이터를 찾아야 할때 사용 시간복잡도는 O(N)이다. 이진 탐색 데이터가 정렬되어 있어야만 사용할 수 있는 알고리즘이다. 시작점,끝점,중간점으로 범위를 나누어 탐색한다. 찾으려는 데이터와 중간점 위치에 있는 데이터를 반복적으로 비교해서 데이터를 찾는다 STEP 1 시작점과 끝점을 확인한 다음 둘 사이 중간점을 시작점과 끝점을 더한 값을 2로 나눈 값으로 한다. 다음으로 중간점[4]의 데이터와 8과 찾으려는 데이터 4를 비교한다. 중간점의 데이터 8이 더 크므로 중간저 이후의 값은 확인 할 필요가 없다. 그래서 끝점을 [4]의 이전인 [3]으로 변경 STEP 2 1과 ..